Provides infrastructure layer compute capabilities, including both bare metal and virtual servers with various optimizations includins compute, memory, IO, and disk. Also supports accelerations options such as GPUs, FPGAs, Inferentia and Trainium.
Provides image recognition capability for images (in batch or real-time) and video that provides a analysis of the content such as real-world objects, faces, celebrities, and path mapping.
Provides a publish/subscribe notification service with multiple subscription types including Amazon Simple Queue Service (SQS), Amazon Kinesis Data Firehose, AWS Lambda, generic HTTPS endpoints, SMS and email.
A serverless, fully-managed, message queue service that supports producing, store, and consuming messages and enables loose coupling between applications.
Provides private networking capability spanning multiple availability zones and supporting subnets, routing, network access control groups, security groups and gateways.
Provides tracing of service invocations in distributed applications for observability, allowing users to diagnose issues or optimize their service interactions.
All about Cloud, mostly about Amazon Web Services (AWS)
Why the DynamoDB Accelerator (DAX) is a better cache
2018-05-16 / 621 words / 3 minutes
Sometimes we just don’t get the performance from our IT systems that we need. A compute-intensive task cannot process quickly enough, or a data-intensive task cannot read from the filesystem quickly enough. Solutions exist for various different types of performance problems such as parallelism and buffering. Even highly performance data stores like Amazon DynamoDB may not be fast enough. One solution a cache, which is effectively what the Amazon DynamoDB Accelerator (DAX) is.
What is a Cache?
Wikipedia describes a cache as:
[…] a hardware or software component that stores data so future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation, or the duplicate of data stored elsewhere. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests can be served from the cache, the faster the system performs.
To be cost-effective and to enable efficient use of data, caches must be relatively small.
AWS themselves offer the Amazon ElastiCache Service, which provides managed services for the Memcached and Redis caching engines. These engines will store both the result of an earlier computation, or the duplicate of data stored elsewhere. DynamoDB Accelerator (DAX) is only caches data from DynamoDB.
To use a cache, the usual steps are:
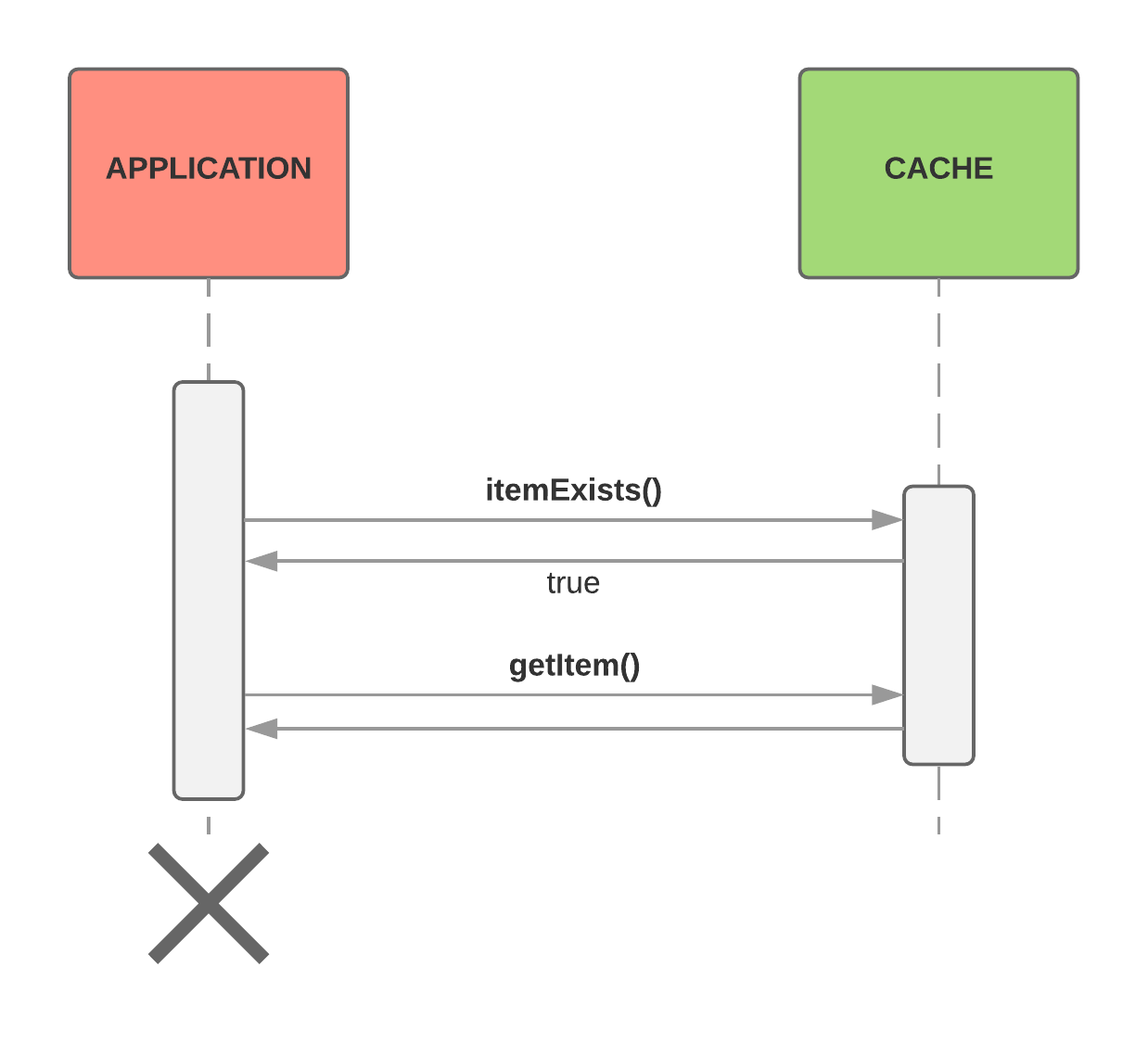
The application checks the cache to see if the item exists
If it does exist (a cache hit):
read the item from the cache
Cache Hit
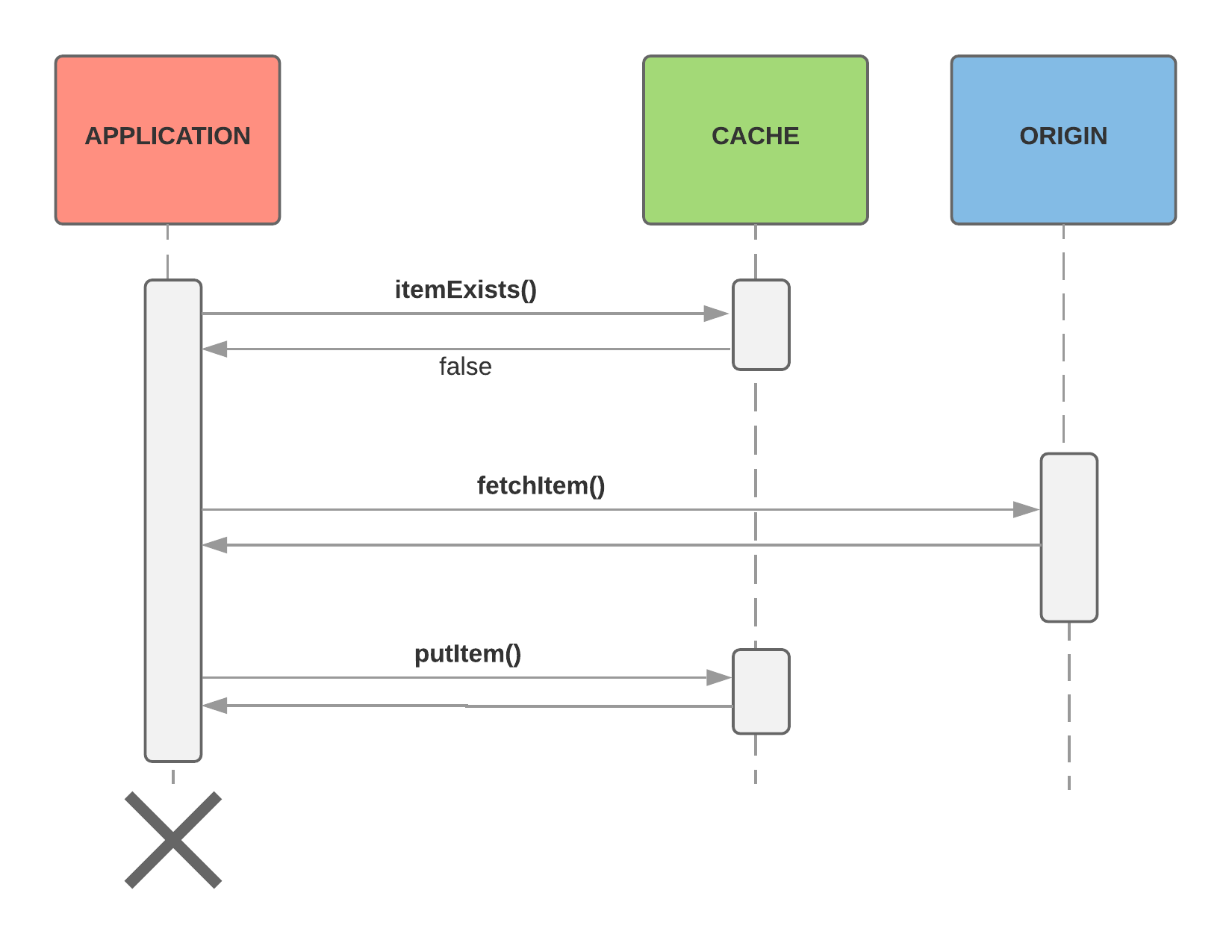
If it does not exist (a cache miss):
read the item from the origin (this may take a significant period of time and/or resources)
store the item in the cache
Cache Miss
As the cache fills, flushing removes items to keep caches small. One algorithm used to flush data from a cache is Least Recently Used (LRU), but many others a list on Wikipedia.
Issues with Data Caching
Personally, I’m not a fan of caches or caching for two main reasons.
First, unless you have complete control over updates to the data, it is possible for another entity to make an update. You then have a decision to make. Do you invalidate the cache more frequently, or do you risk returning stale data? If you invalidate the cache too frequently, you lose the benefit of having the cache.
Second, the application needs to be acutely aware of the cache. It needs to check the cache, read from the cache and write to the cache. It still needs to be able to write to the origin and read from the origin. We’ve added complexity and an entirely different data store to integrate with which leads to more code, more libraries and more bloat.
How DAX is better
DAX is quite specialized. Applications which currently use DynamoDB but need even better performance are the intended audience for DAX. Those applications already make extensive use of the DynamoDB API to read from and write to DynamoDB.
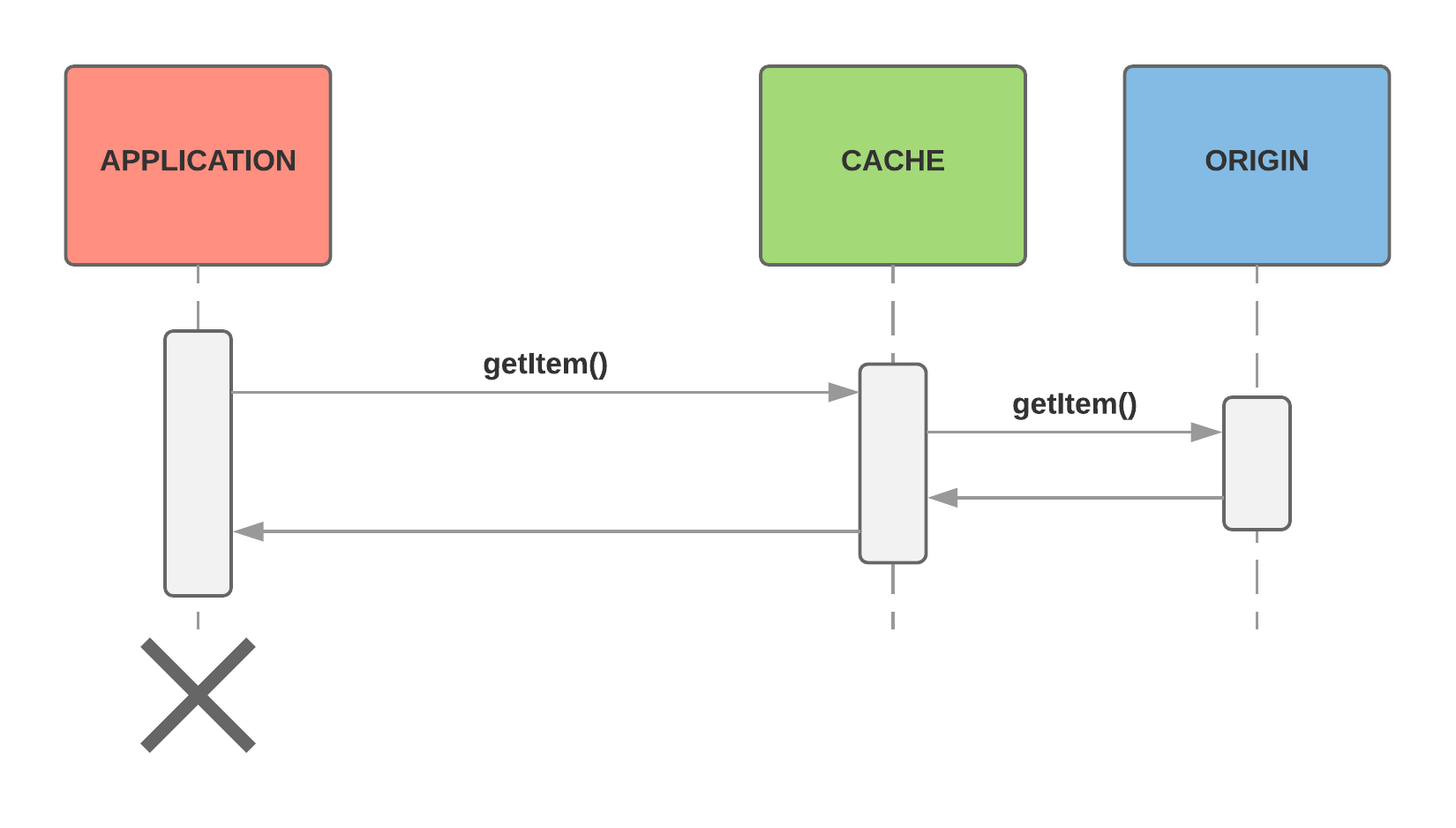
In order to make it easy to use DAX, AWS made the API for working with DAX identical to the API for DynamoDB. In order to eliminate extra code dealing with the origin, DAX acts as a proxy. Instead of the application dealing with the origin when a cache miss occurs, DAX deals with the origin instead.
DAX
Using this model, you can test the performance characteristics of the application before the deciding whether to use DAX. After launching and configuring DAX, the application simply needs to point at DAX instead of DynamoDB. This takes just a few lines of code.
All data and information provided on this site is for informational
purposes only. cloudninja.cloud makes no representations as to accuracy,
completeness, currentness, suitability, or validity of any information
on this site and will not be liable for any errors, omissions, or
delays in this information or any losses, injuries, or damages
arising from its display or use. All information is provided on an
as-is basis.
This is a personal weblog. The opinions expressed here represent my
own and not those of my employer. My opinions may change over time.