Provides infrastructure layer compute capabilities, including both bare metal and virtual servers with various optimizations includins compute, memory, IO, and disk. Also supports accelerations options such as GPUs, FPGAs, Inferentia and Trainium.
Provides image recognition capability for images (in batch or real-time) and video that provides a analysis of the content such as real-world objects, faces, celebrities, and path mapping.
Provides a publish/subscribe notification service with multiple subscription types including Amazon Simple Queue Service (SQS), Amazon Kinesis Data Firehose, AWS Lambda, generic HTTPS endpoints, SMS and email.
A serverless, fully-managed, message queue service that supports producing, store, and consuming messages and enables loose coupling between applications.
Provides private networking capability spanning multiple availability zones and supporting subnets, routing, network access control groups, security groups and gateways.
Provides tracing of service invocations in distributed applications for observability, allowing users to diagnose issues or optimize their service interactions.
All about Cloud, mostly about Amazon Web Services (AWS)
Converting Apache Avro to Apache Parquet Using Amazon Athena
2020-01-20 / 640 words / 4 minutes
Converting files between various formats is a fact of life for IT staff. This is often because different formats are optimized for specific use cases. For example, JPEG files are great for photographs and use lossy compression that can be almost impossible for the human eye to detect by PNG files are great when logos or graphics need to preserve every pixel in an image.
Apache Avro and Apache Parquet are similar examples. This post explains the benefits of each file format, and demonstrates how to convert between the two formats using Amazon Athena.
About Apache Avro
Apache Avro is a row based format which means that data within the file is arranged with all of the first row occurring before all the second row. This approach has been used for most transactional databases for many years and is great for streaming IO operations. For example, you can write a program to open an Avro file in an Amazon Simple Storage Service (S3) bucket, read a small part of it, process a few records, write some data out, and then read another small part of it. Using this approach large files can be processed by a resource constrained system, although it can take some time to process the files in a serial manner.
About Apache Parquet
Apache Parquet is a columnar format which means that the first column of all the rows are stored first, then the second column of all the rows are stored. This approach has been pioneered by analytical systems such as Amazon Elastic MapReduce (EMR) and Amazon Redshift because they save significant disk access when only a subset of a row is required. While Parquet is highly optimized for reading only part of a row, it is much more difficult to insert new rows into a columnar store, and more difficult to work with entire rows because data related to a single row is spread across the entire file. These challenges are often offset because Parquet files are usually processed by large clustered analytics systems such as EMR.
Conversion
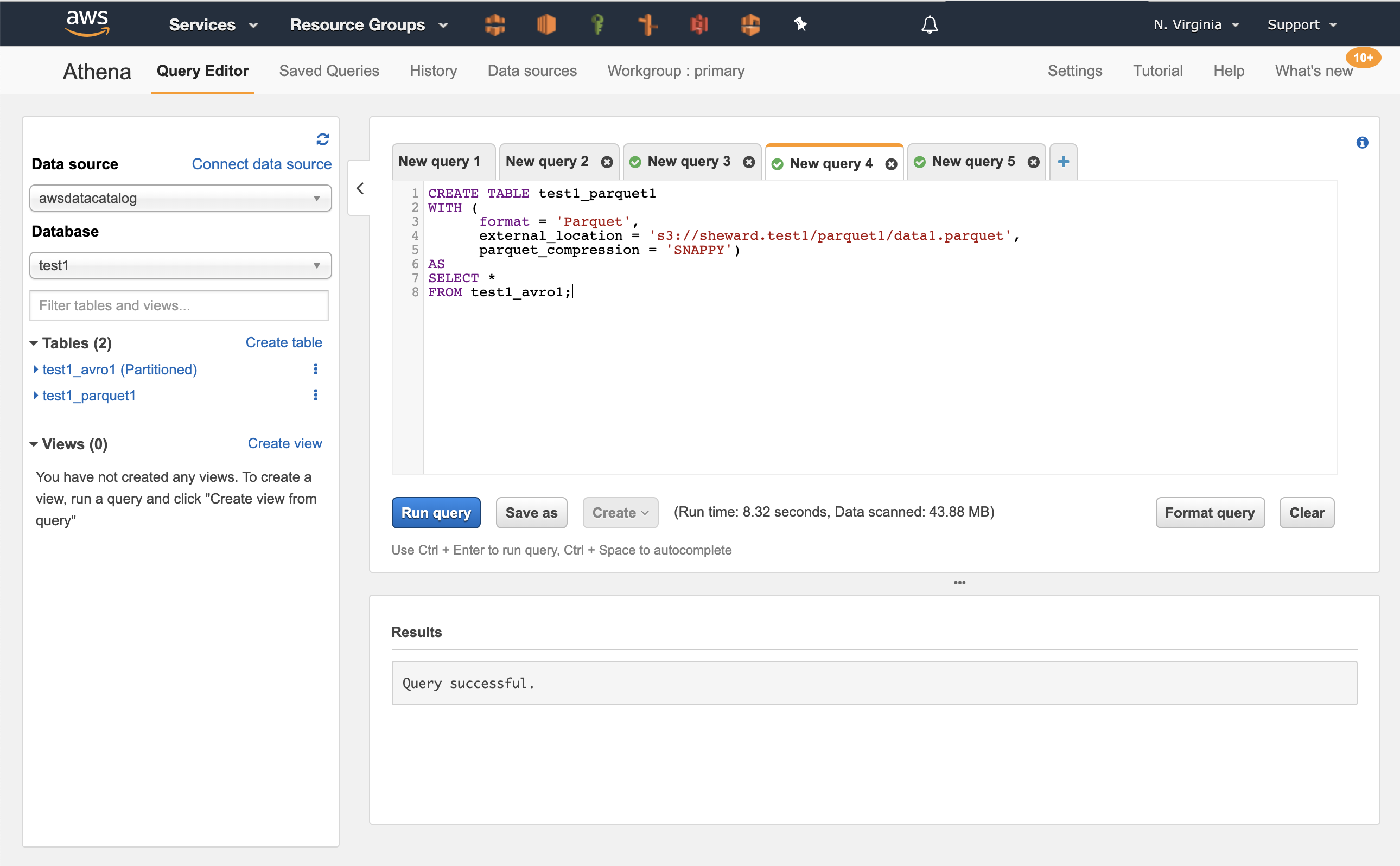
The conversion between the two data types is fairly straightforward using Amazon Athena. The “CTAS” (“CREATE TABLE AS”) functionality which was added allows an Avro file to be quickly converted using a single Athena command. The exact command is:
CREATETABLE test1_parquet1
WITH (
format ='Parquet',
external_location ='s3://<bucket name>/parquet1/data1.parquet',
parquet_compression ='SNAPPY')
ASSELECT*FROM test1_avro1;
The command creates a new table called “test1_parquet1”. The “AS” section uses the output from the “SELECT * FROM test1_avro1” SQL command to define the fields and data. The “WITH” section of the file defines the format to create (“Parquet”), the Amazon Simple Storage Service (S3) bucket in which to store the new file, and specifically for the Parquet file format, the compression format to use on the file. The output from running the command can be seen below:
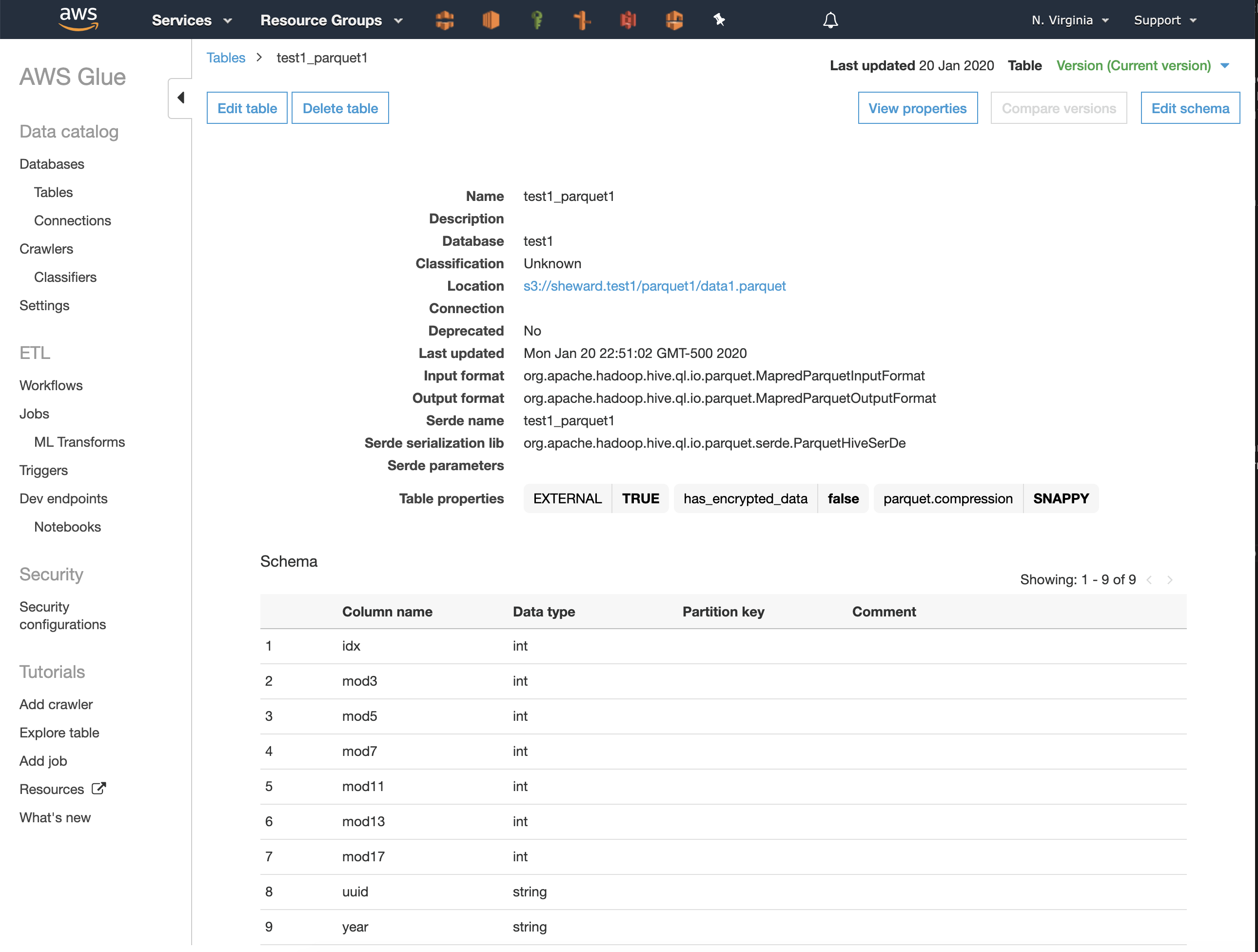
You can see from the figure that the query took 8.32 seconds to execute, and scanned 43.88 MB of data, which is the entire size of the data1.avro file. You can also see that the Parquet backed table has been listed on the right hand side of the Athena console, beneath “test1_avro1” and if we check the AWS Glue console, we can see that the Parquet file exists there too:
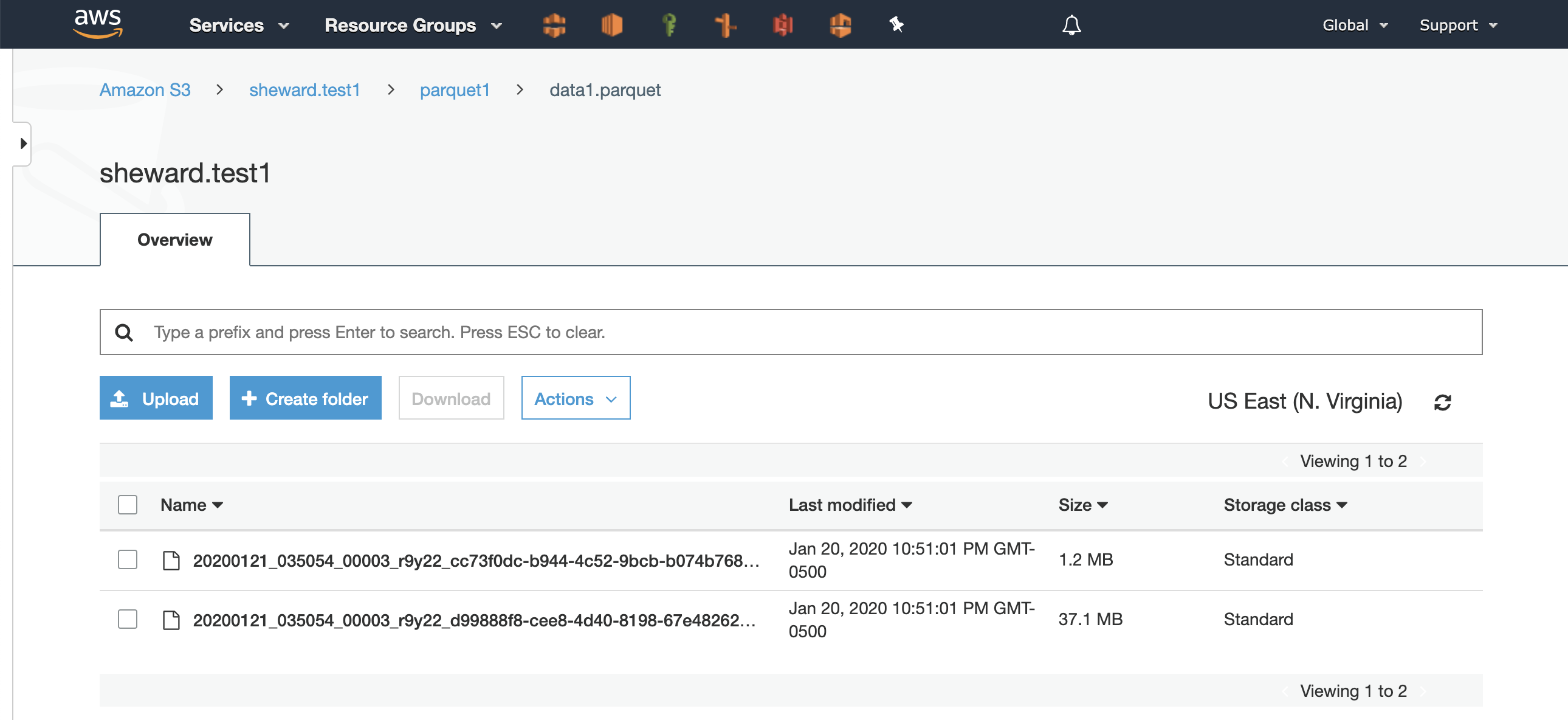
Interestingly though, if we check Amazon Simple Storage Service (S3), we can see the Parquet representation was broken across two files in the S3 Bucket:
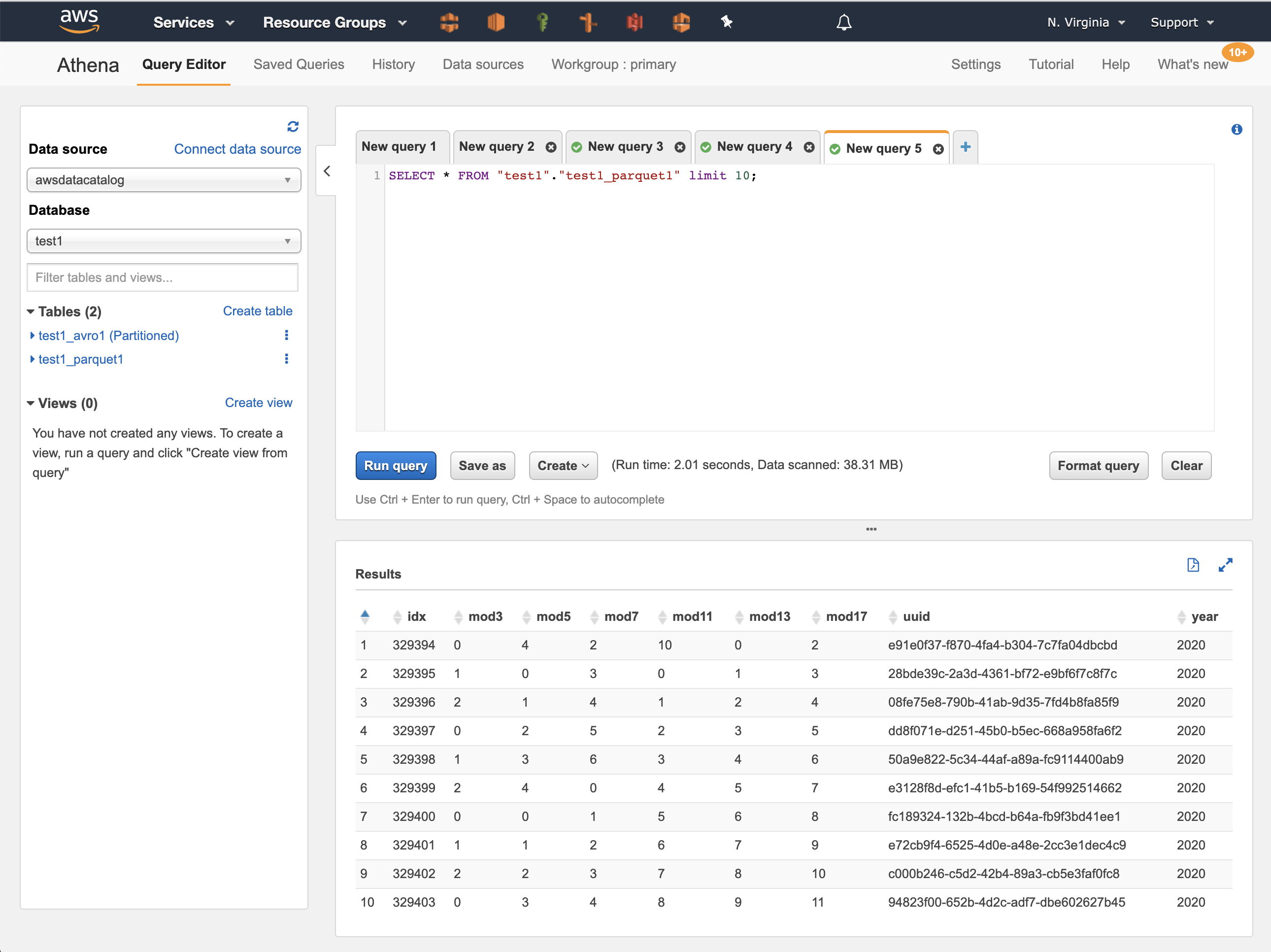
Again, we can verify that Athena can query the data in the Parquet backed table by again clicking on the three vertical dots by the side of the table name (“test1_parquet1”) but this time by selecting “Preview table”. The query executes and the output is shown below:
Conclusion
Using Amazon Athena to perform conversions between Apache Avro and Apache Parquet is fast and simple.
All data and information provided on this site is for informational
purposes only. cloudninja.cloud makes no representations as to accuracy,
completeness, currentness, suitability, or validity of any information
on this site and will not be liable for any errors, omissions, or
delays in this information or any losses, injuries, or damages
arising from its display or use. All information is provided on an
as-is basis.
This is a personal weblog. The opinions expressed here represent my
own and not those of my employer. My opinions may change over time.