Provides infrastructure layer compute capabilities, including both bare metal and virtual servers with various optimizations includins compute, memory, IO, and disk. Also supports accelerations options such as GPUs, FPGAs, Inferentia and Trainium.
Provides image recognition capability for images (in batch or real-time) and video that provides a analysis of the content such as real-world objects, faces, celebrities, and path mapping.
Provides a publish/subscribe notification service with multiple subscription types including Amazon Simple Queue Service (SQS), Amazon Kinesis Data Firehose, AWS Lambda, generic HTTPS endpoints, SMS and email.
A serverless, fully-managed, message queue service that supports producing, store, and consuming messages and enables loose coupling between applications.
Provides private networking capability spanning multiple availability zones and supporting subnets, routing, network access control groups, security groups and gateways.
Provides tracing of service invocations in distributed applications for observability, allowing users to diagnose issues or optimize their service interactions.
All about Cloud, mostly about Amazon Web Services (AWS)
Working with Apache Avro in AWS Glue and Amazon Athena
2020-01-19 / 909 words / 5 minutes
When working with “big data” analytics systems, the de facto standard file system format is Apache Parquet. Parquet is a columnar format, meaning that unlike more transactional processing systems which arrange their data in row order, the data is arranged in columns instead. This has the benefit of reducing the amount of data which must be read if only a few columns are required, but the disadvantage that inserts, updates, and record (row) based processing may be slower. An alternative to Apache Parquet is the Apache Avro file format. It is row-based, supports an embedded schema and can be processed by Amazon Elastic MapReduce (EMR), Amazon Athena, Amazon Redshift and AWS Glue.
Creating an Apache Avro File
We’ll start with some code to create an Avro file, which starts with an Avro schema. In this simple, but very contrived example, we’re storing a few integers, and a UUID. The Avro schema is:
I wrote a quick Java program to generate an Avro file. There’s a couple of ways to do this. One is using code generation, which generates a Java class representing the Avro schema. I chose not to use code generation in this example. The code is:
When executed, the file data.avro is created. The file is then uploaded to S3 and we use an AWS Glue crawler to discover the data. Athena is a bit picky in how it finds the data. For my first attempt I simply copied the file to the root of the S3 bucket. Although AWS Glue was able to find the data, Athena didn’t seem to be able to query it. I then copied it into a subdirectory (called “year=2020”) of a subdirectory (called “avro1”) of the root folder and both AWS Glue cataloged it, and Amazon Athena was able to query it. The command I used was:
I tried reusing an AWS Glue crawler from a previous session which used a different bucket. The IAM role that the crawler used to search the bucket was given access only to a different S3 bucket and failed to catalog the tables. This would have been immediately obvious if there was an error generated, but I didn’t see one. By trial and error I realized the problem and the tables were cataloged.
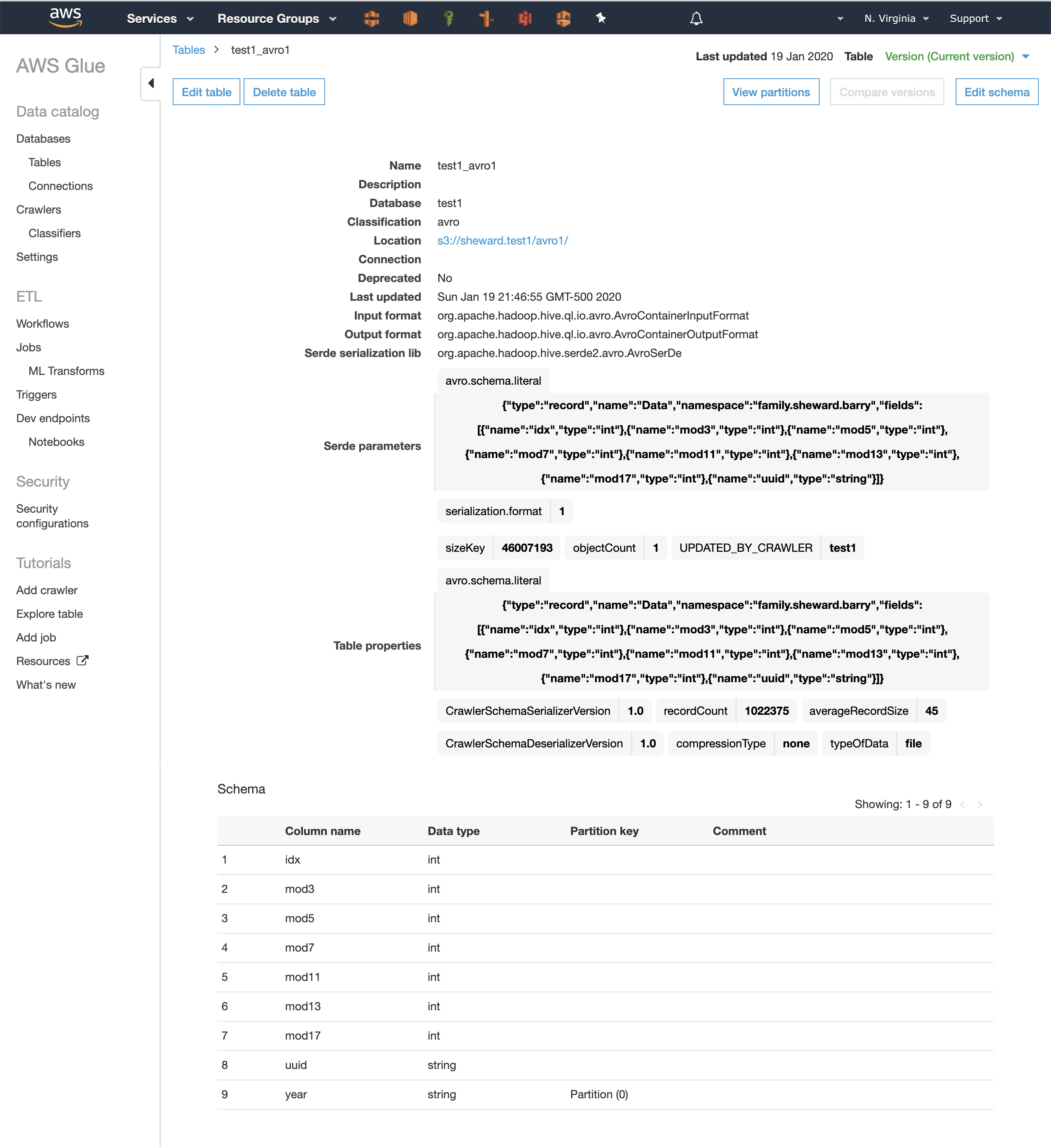
One benefit of Avro with its embedded schema is that the Glue crawlers really don’t need to guess at the data types. The result is shown below:
Preparing Amazon Athena
One we have the defined the table, we can query the data using Amazon Athena. Amazon Athena is a fully-managed AWS Service offering SQL-like queries across “big data” sets. It is build on Presto, and charges per MiB of data scanned. This makes it a great choice for low-volume experimental usage.
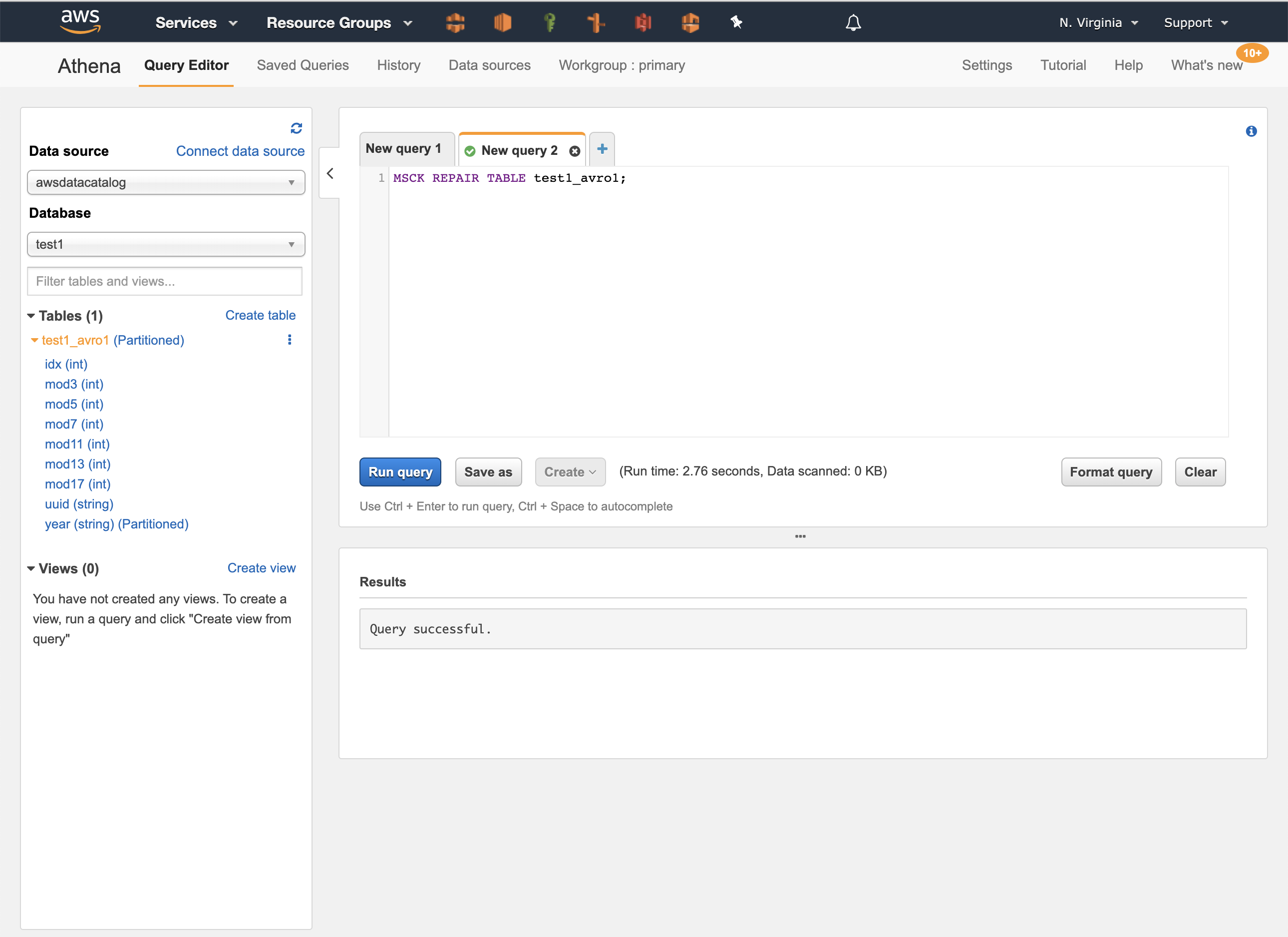
Once the Amazon Athena console is opened, and the AWS Glue database is selected (“test1” in this example), the list of tables is listed. First, we run a command to ensure that the table partitions are discovered. This can be achieved by clicking on the three vertical dots by the side of the table name and selecting “Load partitions”. The query automatically executes and the output is shown below:
Executing Queries using Amazon Athena
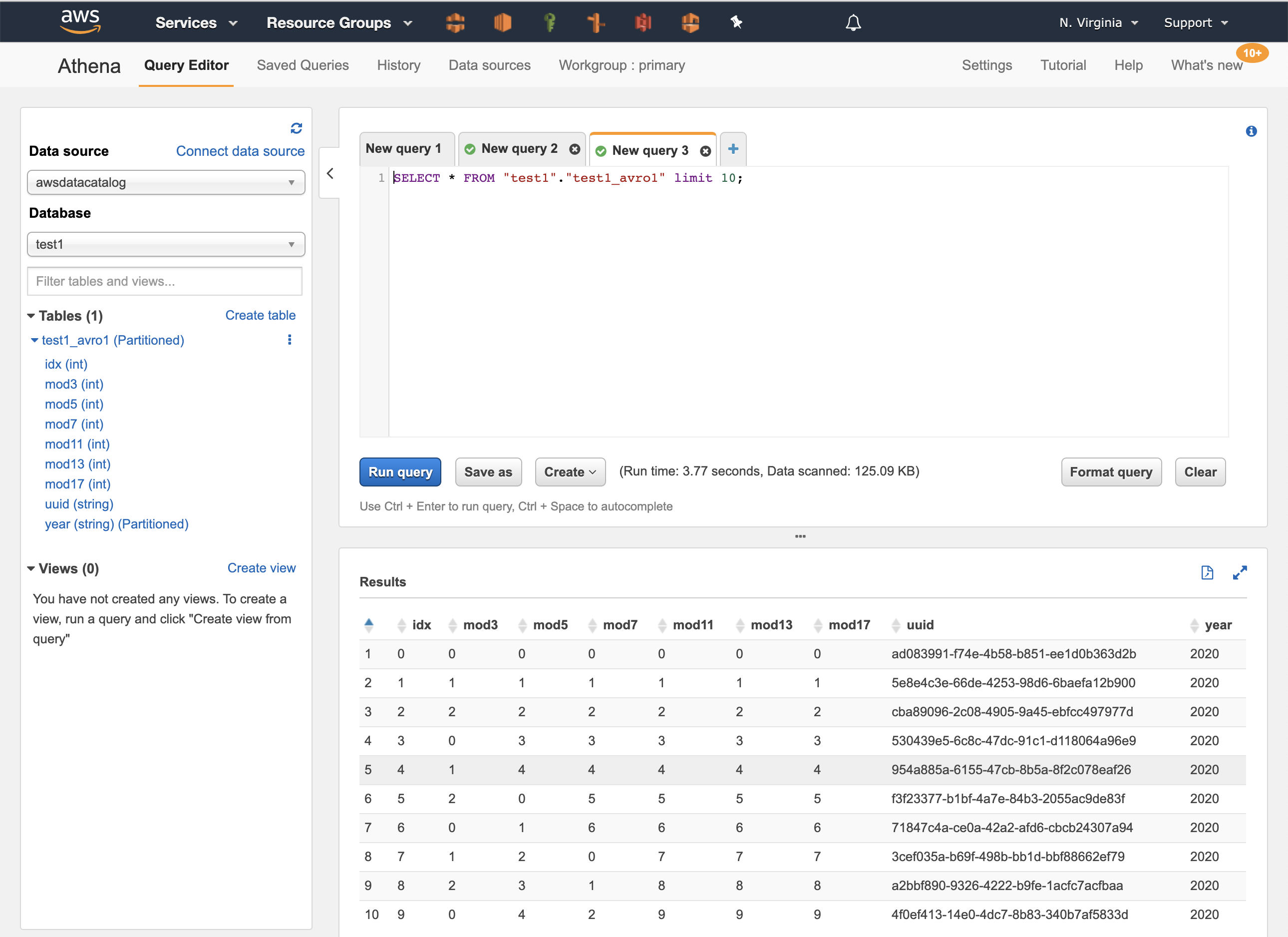
Next, we can verify that Athena can query the data by again clicking on the three vertical dots by the side of the table name but this time by selecting “Preview table”. The query executes and the output is shown below:
Conclusion
Apache Avro is an alternate to Apache Parquet which uses a row-based storage format rather than a columnar storage format that works well with “big data” analytics tools such as Amazon Athena, Amazon Redshift, Amazon EMR and AWS Glue.
All data and information provided on this site is for informational
purposes only. cloudninja.cloud makes no representations as to accuracy,
completeness, currentness, suitability, or validity of any information
on this site and will not be liable for any errors, omissions, or
delays in this information or any losses, injuries, or damages
arising from its display or use. All information is provided on an
as-is basis.
This is a personal weblog. The opinions expressed here represent my
own and not those of my employer. My opinions may change over time.